آستانه درصد گوگل برای شناسایی محتوای تکراری

جان مولر از گوگل اخیرا به این سوال پاسخ داده است که آیا آستانه درصدی برای شناسایی محتوای تکراری وجود دارد که گوگل از آن برای شناسایی و فیلتر کردن محتوای تکراری یا Duplicate Content استفاده کند.
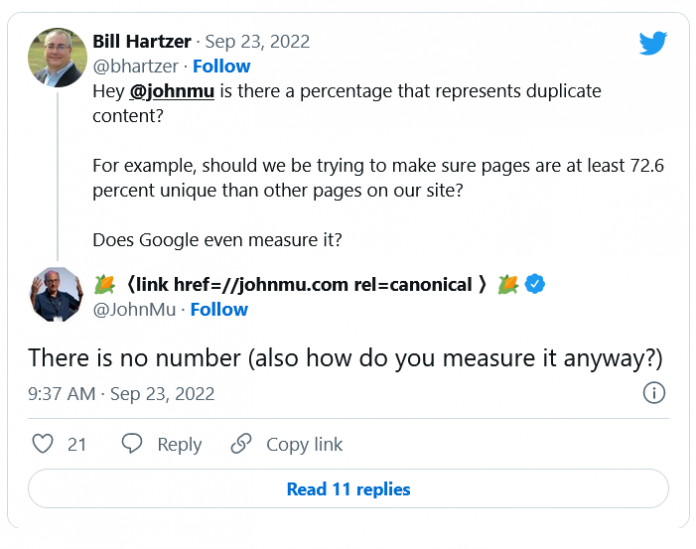
چند درصد برابر با محتوای تکراری است؟
مکالمه در فیسبوک زمانی شروع شد که شخصی پرسید آیا کسی میداند موتور جستجو گوگل درصدی از همپوشانی محتوا را منتشر کرده است که در آن محتوا تکراری در نظر گرفته میشود. جان مولر نیز بلافاصله به سوال این کاربر درباره شناسایی محتوای تکراری توسط گوگل پاسخ داد:
روش گوگل برای شناسایی محتوای تکراری سال هاست که به طرز قابل توجهی مشابه است. در سال 2013، یک مهندس نرم افزار در گوگل، ویدیوی رسمی را منتشر کرد که توضیح میداد چگونه گوگل محتوای تکراری را تشخیص میدهد. او این ویدئو را با بیان اینکه مقدار زیادی از محتوای اینترنتی تکراری است و این یک اتفاق عادی است، شروع کرد.
مهم است که بدانید اگر به محتوای موجود در وب نگاه کنید، چیزی حدود 25٪ یا 30٪ از کل محتوای وب، محتوای تکراری است. مردم یک پاراگراف از یک وبلاگ را نقل قول میکنند و سپس آن را به وبلاگ لینک میدهند. از آنجایی که بسیاری از محتوای تکراری بدون هدف اسپم هستند، گوگل آن محتوا را جریمه نمیکند.
او گفت که جریمه کردن صفحات وب برای داشتن محتوای تکراری تاثیر منفی بر کیفیت نتایج جستجو خواهد داشت.
به صورت کلی طبق پاسخ جان مولر وقتی در مورد محتوای تکراری صحبت میشود، احتمالاً یک آستانه درصد وجود ندارد که گفته شود آن محتوا تکراری است. نکته دیگر این است که به نظر میرسد بین زمانی که بخشی از محتوا تکراری است و تمام محتوا تکراری است، تمایزی وجود دارد.
منبع: searchenginejournal.com